
Day 2–Scale Smart: AI-Powered Content Organization Strategies

— Information Architect and interested in how people find stuff, particularly in large info systems
- Keeping content repositories organized is ongoing challenges that gets de-prioritized
- Market keeps changing and new products come online
— Knowledge base keeps devolving, and users have stuff finding stuff they need
- This challenges content professionals, but those aren’t only focus concerned with publishing content — and keeping stuff organized is an ongoing challenge

— Two types of content repositories and things exposed to end-users and online stores product catalog and support knowledge base
- Knowledge repositories used for internal teams and interview transcripts referred to when synthesizing research
— Finding information is crucial and search alone doesn’t cut it, people might not know what to look for and lack of context for stuff to find in the system
- Things like taxonomies and list of content categories might be useful and outline what to expect looking there
— This all must be defined
- Particular work that happens at very beginning when new system built and is a blank slate
- Initial set of content to categorize
- Second phase has a lot of work that happens after the fact
- As product portfolio evolves content will change and new stuff will be coming in to describe content
- Will go back into content repository and tweak taxonomies and tweak older content to match new categories
— This all takes work and resources
- In today’s environment understandable orgs are looking to focus energies elsewhere in creating new products or features for existing products as opposed to keeping stuff organized
— A lot of the work is unglamorous
- Supports products and features, but not main attraction and focus energies elsewhere
— De-prioritized over time, content becomes less useful and how to keep stuff relevant without requiring we focus on resources on this

— Task is very suitable for AI
- Something AI can do very well compared to humans
- LLMs can organize content very effectively at much larger scale than people can
— As result can get better user experiences and free up teams on tasks that create more correct value for customers

— Experimenting with ways to keep content organized and two use cases experimented with
- Recategorizing existing content with evolving taxonomy and new categories and need to retag older content
- Developing net new taxonomy and coming up with new way of categorizing content

— This scenario is most applicable when you have new content coming into system, but large set of content already there and taxonomy changing for some system and goal to keep things up to date and findable
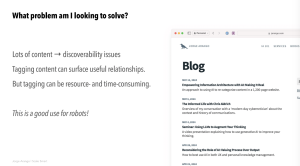
— Experiment focused on my blog which has nearly 1200 posts
- Systems with large back catalog, older content not getting as much visibility as we’d like
— Getting focus for older content and way for older stuff
- Individual links to blog posts in repository
— Technique involved CMS finding posts with common meta-data tags and challenge had with implementing approach while newer posts had three tags, older ones didn’t
- Other challenge was that taxonomy had grown idiosyncratic over time and introduced terms that were meaningful to him, but not end users
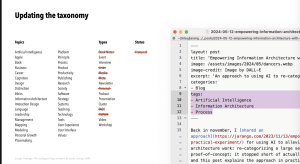
— Started project with LLM to retag posts and began with cleaning up taxonomy and assumption if terms that user to site wouldn’t understand, GPT-4 wouldn’t grasp things either [i.e. acronyms]
— Used standard set of terms and clean taxonomy and retag everything
— Manual effort would take 10-12 hours of tedious work and where LLM helped

— Created script to GPT-4, and LLM to pick three tags from predefined list in prompt and taxonomy
- Approach worked really well and asked GPT-4 not to introduce own terms
— LLM had tags to hallucinate and took steps to effect my content
- Rather than LLM to modify content in CMS, and linked tags to CSV file to open in Excel and review before implementing changes in production
— If you know system will be unpredictable, have agency to make changes and use LLM to create draft product as opposed to production
- Lets you do work at LLM while giving control to final output

— Process reduced activity by about 1/3 and to-do something like this then and would be much shorter than that
- Use of tools

— Second use case dealt with new content categories to develop new content category from scratch
- New systems going through major changes
- Challenge different in previous use case had LLM examining content one post at a time and wouldn’t work for use case
— Have LLM look at entire corpus of work in one go
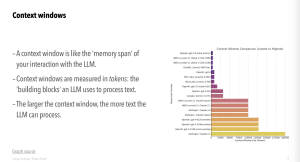
— Optimized to work with short snippets of text
- Context window that is limited, equivalent to what LLM could work at any given time
— GPT 4o as most popular model is equivalent to 128,000 token, 350-500 pages of text. Large but smaller than what you might need to process an entire repository
- You also don’t want to send content to LLM
— Risk of getting lost in weeds, where LLM can’t really think holistically by default
— Take steps to prepare your content before bringing LLM in
- Chunk content in more granular units you can build relationships between
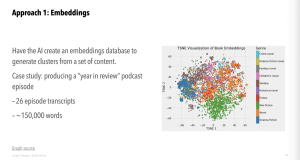
—First approach dealt with embedding database, and having LLM build database to store chunks of text for statistical relationships between them
- Using embedding database, to find clusters of related content
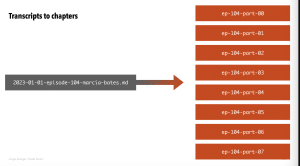
— Leveraged my “Year in Review” podcast episode, and had transcripts into sections of those little snippets and used GPT-4 to suggest clusters of related topics between snippets
- Experiment!
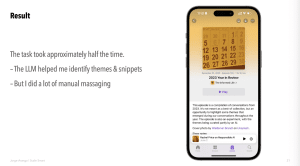
— Experiment was somewhat successful, topics it suggested weren’t helpful in his view
- Did catch themes and relevant snippets of conversation to edit into show
— Saved half time of manual process
- Expect even more time to be saved
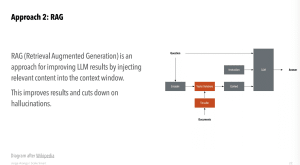
— That said, think won’t do it again, but will try approach of RAG
- Retrieval Augmented Generation, which merges search capabilities with LLM and finds relevant content in a repository you provided into context window so answers can be more precise
— Working with Claude or GPT, you can’t ask it about stuff in your computer, and RAG lets you run queries on things LLM haven’t bene trained on
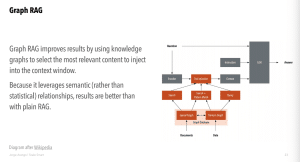
— View of Graph RAG and looking for snippets of text, and running query using knowledge graphs rather than plain snippets of text
- Improves precision of LLM, by introducing semantic relationships between concepts
- Lets you prompt LLM at specific levels of abstraction
— Using approach for client website and really cool to

— Bespoke LLM to ask about content of website and new taxonomies as bonus, eliminated Lorem Ipsum text in wireframes

— Big takeaway was seeing things as tool for working with language
- Increased speed efficiency and efficacy as IA, giving ideas on new kinds of things that can be done

— Three lessons to take away from experiences
- LLMs really work to organize content at scale, but can’t do automatically
- Allow us to augment on what matters most and not replace
- Checkpoints to tweak these things and more quality
- Working with different tools requires different workflows
- Tools bring new capabilities and constraints, and wildly overhyped or pessimistic
- Real constraints and exciting possibilities and only way to get taste for what those might be, by getting stuff done

— I’d like to encourage you to learn about technologies hands-on, especially if you work with language at all— as tools are accessible and easily able to figure out
- Sharing things like experiments presented today and deeper posts to look at along with prompts
Q&A
- Have you seen examples of this outside of own datasets?
- Doing work with one client project right now, but very rightful for concerns over things like privacy and reluctance to share things with a model provider
- Experimenting with local models like Llama
