
AR2021-Humanizing AI: Filling the Gaps with Multi-Faceted Research (Joel Branch, Lucd)

—> Good afternoon! I work at a Lucd, a company that helps other enterprises get their AI roadmaps planned out

—> There is a lot to be excited about regarding AI
-
Examples like automation in cars that help you stay in your lane, and automated driving
-
Deep Fakes are an example as well
—> My observation is that AI is uninformed and hurried, resulting in deployments that don’t operate well in real world
-
Reasons for this include infrastructure limits, and a lack of talent
—> But a major reason is a lack of humanized AI
-
Our goal should be creating governance frameworks that democratize the development of AI solutions
-
Not creating interfaces like Google Home or Alexa
-
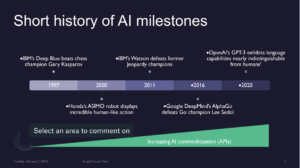
—> AI is not new, and is as old as computing itself, but lot of breakthroughs in past 25 years have caused advancement and overall popularity of the discipline
—> Popular milestones include :
-
1997, Deep Blue beating Gary Kasparov
-
2000, ASIMO robot displayed human-like actions
-
2011, IBM Watson beating former Jeopardy champions
-
2016, DeepMind beating the world Go champion
-
2020, GPT-3 program exhibited language capabilities that could mimic human writing
—> AI commoditization has increased as we have moved through time
-
Lot of key AI technology is just an API call away, with minimal code required
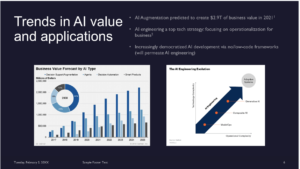
—> Next, I want to cover next trends in AI value and applications
—> Trends for AI are quite attractive
-
Gartner expects AI augmentation will creation trillions of dollars in business value
-
What do I mean by AI augmentation?
-
Not chatbot through customer service flow, but rather how augmentation helps business work better, from analyzing data, to writing reports
-
—> AI engineering is also a top tech strategy
-
Developing AI through low to no-code frameworks, and hiring people with deepest AI backgrounds

—> Next I want to talk about the state of AI Deployments, from the enterprise perspective
-
Even with hype and capabilities, AI efforts are largely failing
—> Companies report little to no impact from AI, and close to 90% of data science projects and don’t make into production

—> So why is enterprise AI failing?
—> For many reasons, and not just infrastructure problems
-
Differentiating factor and problems
—> Starting point is a lack of organizational support
-
AI limited to certain projects
-
There is a limited supply of AI talent
-
AI Development teams are composed of near exclusively AI-related talent
-
In my prior work at ESPN, my own AI work was isolated from the rest of ESPN’s organization
-

—> Next I want to talk about the state of AI Deployments, from the enterprise perspective
-
Even with hype and capabilities, AI efforts are largely failing
—> Companies report little to no impact from AI, and close to 90% of data science projects and don’t make into production

—> There are also adoption challenges,
-
Close to 50% of effort is spent on data access and cleaning
—> There is black-box decision-making
-
Lack of transparency and rationality in AI output produced
-
AI, for context, works as probabilistic learning, with no hard or fast decisions
- Done with network of nodes and layers
-
Understanding why AI made a decision is hard to understand
-
Information goes in, something comes out, but no clear idea why
—> AI Bias
-
Examples of race bias in online ads, job postings, etc.
-
Fueled by overly technically driven solutions, and having a lot of engineering staff at the table
- But this is missing non-technical rules that can handle bias

—> Example of Gender Shades project which analyzed accuracy of facial recognition companies like Microsoft, Face ++, IBM
-
Evaluated accuracy of algorithms, and data-set to balance among gender and skin types in training data used by AI
—> Exposure of biased performance resulted in internal reviews at Microsoft and IBM
—> The results?
-
Some facial detection algorithms do better with men rather than women
-
Unfairness in lighter/darker color subject is significant going from 97%, to 75% accuracy
-
Bias problem gets worse, the more features are interested
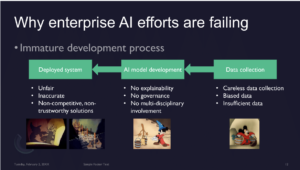
—> AI efforts are also failing through an immature development process
-
Short process with immature orgs/deparments that follow on process
—> There’s straightforward data collection, but with biased or insufficient data
—> People then directly create a model, without explainability (on their laptop, with little expert oversight)
-
Lot of work is not tracked, unversioned one
-
Little to no audit trail
—> Goes right into deployed system and begins causing a mess
-
AI is inaccurate, unfair, or non-trustworthy

—> To recap, we talked about why you should care about AI, even with just a financial point of view
—> Then discussed why AI is failing
-
Largely caused by technical talent being left to their own devices
—> So, what do we do?
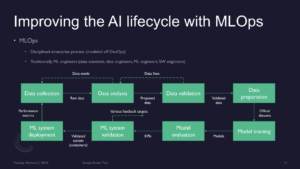
—> First order, address development workflow shown earlier
-
Overall, benefits of MLOps (borrowed from DevOps) offers governance, accountability, clear stakeholder responsibilities, to manage AI deployment
-
Distinctly have phase for data analysis
-
Have phase for validating data, if data is invalid or inaccurate can go backwards
-
-
Also work to prepare data and make sure the data that goes into model is good for production
—> Then you finally have ML system deployment
-
Still this is only part of the solution, as guidelines emphasize roles of engineers
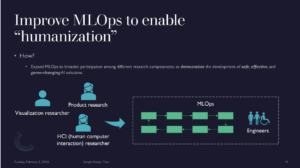
—> We expand number of people brought into ML Ops process, and add people to mix, including a product researcher and AI ethicist to make sure it’s all developed responsibility with target customer in mind
—> How do we get to include these folks?
-
Enter product researcher and HCI researcher

—> Relevant challenges
-
Exploding amount of data, and dimensions associated with data
-
Data is getting bigger and wider
-
-
Intersectional bias (hard to identify)
—> Two solutions
-
Latent Space Data Exploration: New ways to visualize data in multi-dimensional data, and seeing relationships between data, so people can catch bad data
-
Data Sub-Group Analysis: Identifying sub-groups for comparative analysis through AI
-
Need visualization experts to take audit specialists to essentially look at different groups in AI training data, and compare the results of different data sets as close as possible
-

—> Example of latent space data- Visualizing how digits are grouped together in a latent space, where 12*12 features are grouped
-
It’s then a matter of figuring out if data can be separated

—> Challenges in HCI
-
Explainability: Lack of explainability of AI models, limits capacity of deployment and evaluation
-
MLOps requires a lot of automation, but this process is still premature, and requires people to have AI domain knowledge
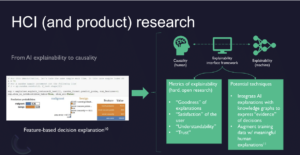
—> Next, I’ll show a slide on AI explainability
-
Left-hand side shows features and values. Visual of AI model that listed out features key to making its decisions
—> We just don’t want explainability for ML engineers, but want to get causality as well
-
HCI experts need explainability framework to create something cognitively understandable for humans
-
Includes metrics of explainability (i.e. goodness of explanations)
-
—> Can integrate AI explanations with knowledge graphs or ontologies, and interpret AI into something humans can understand
-
Or augmenting training data used for AI models with features that can be expressed by a human

—> Humane AI is necessary, important, as it’ s maturing, and many open problems exist and require a cross disciplinary focus
—> Thank you!
Q&A
- Is there a meta-pattern or algorithm for QA-ing AI systems for other features (other than biological features)?
A: There are explainability techniques that are specifically for medical/biological arena, and for Natural Language processing
—> There might be other QA techniques, but can’t name any right now
2. Is there a heuristic that you use to help you look for problems that only reveal at scale?
A: What he’s seen is that discipline of monitoring of models in production.
-
If you have model in production, do a warm-start of a new model
-
Don’t just start new recommendation engine on January 1st
-
-
Also do synthetic data analysis (when you don’t have enough training data for particular domain)
-
You can use as much data as you can from Internet as a proxy
-
Be willing to give models time, and a distribution of daily data
-
3. Not sure if I’m following this correctly, is latent space visualization effectively just visualization of parameters identified by exploratory factor analysis
—> No, latent space focuses on compression of data such as text data or image data
-
Looks at how you can compress multi-dimensional data into a simpler-dimension data (i.e analyzing three dimensions instead of thirty dimensions )
-
Look at PCA to see what it means to go from high to low dimensional space for latent sapce
—> You are visualizing features, not parameters
-
Technique isn’t perfect, in that you have to work with parameters in order to see if there are ways data can be clustered in any way
-
Techniques exist to help automate that
-
4. What’s our current knowledge about AI trust? What do we know and the gap?
A: It’s evolving. Hard to say what we know about AI trust, since it’s evolving
-
Tools we have now fall into combination of explainability analysis and visualizing explainability
—> Ultimate goal of AI trust is for human being to ask question to the AI, and the AI to explain to the human convincingly why it gave a specific answer to them over other answers.
-
Needs to have back and forth between person and AI
